Content customization and composition in diffusion
Oct 2024
US App. 18/913,107
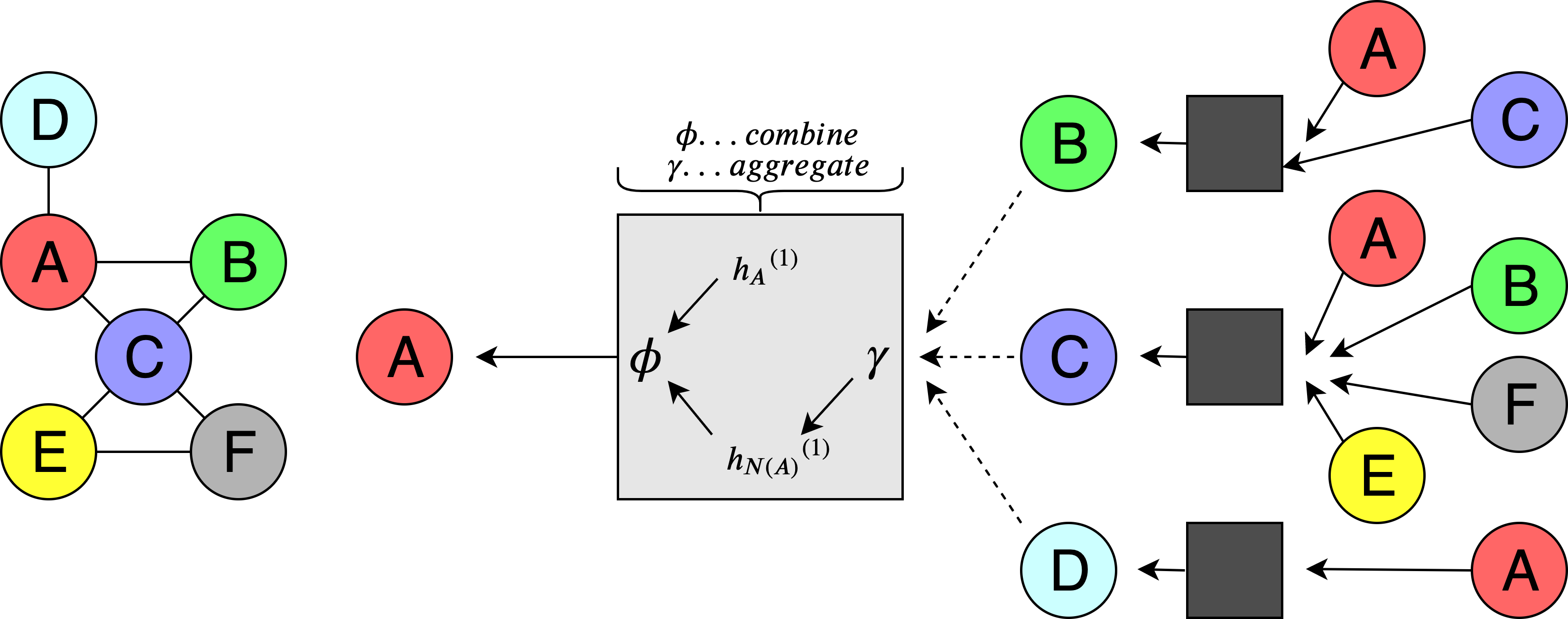
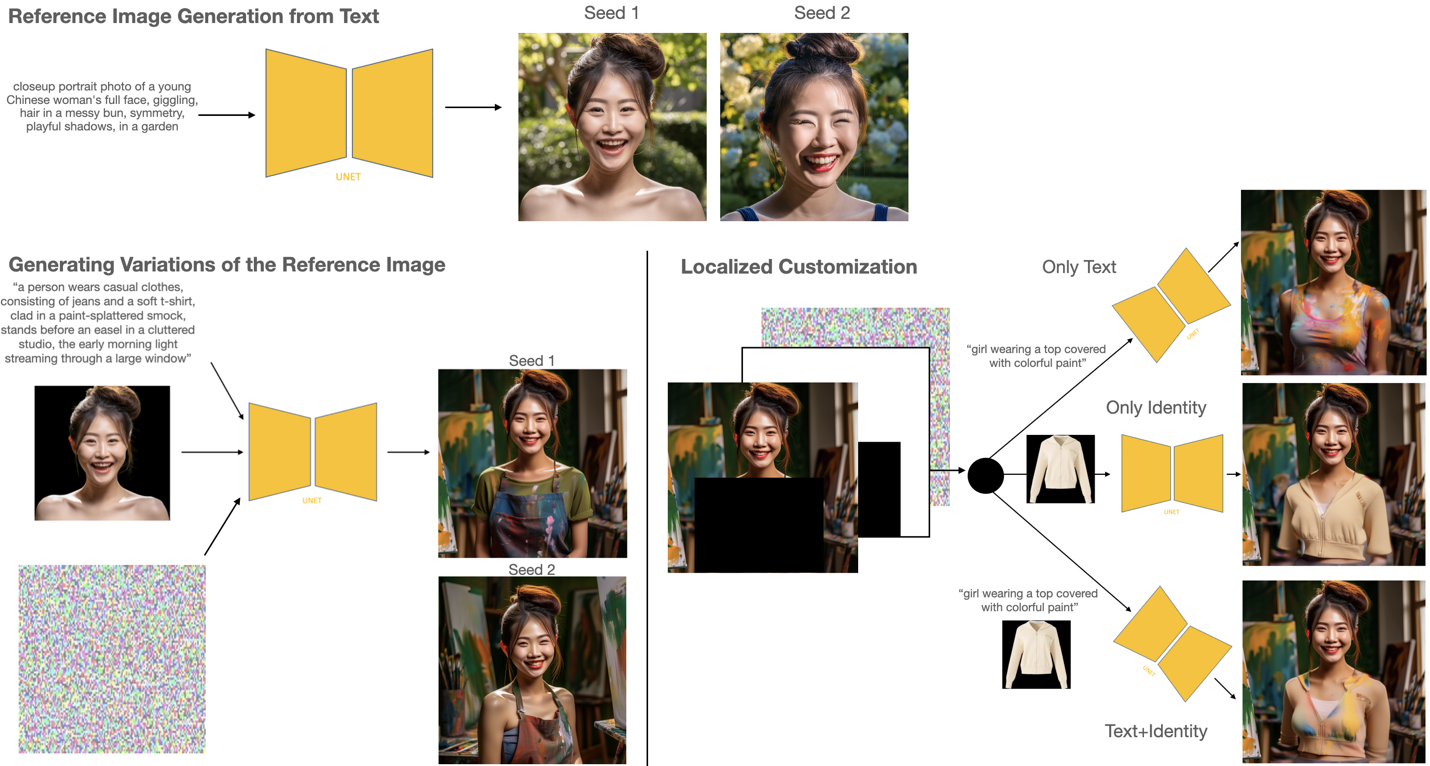
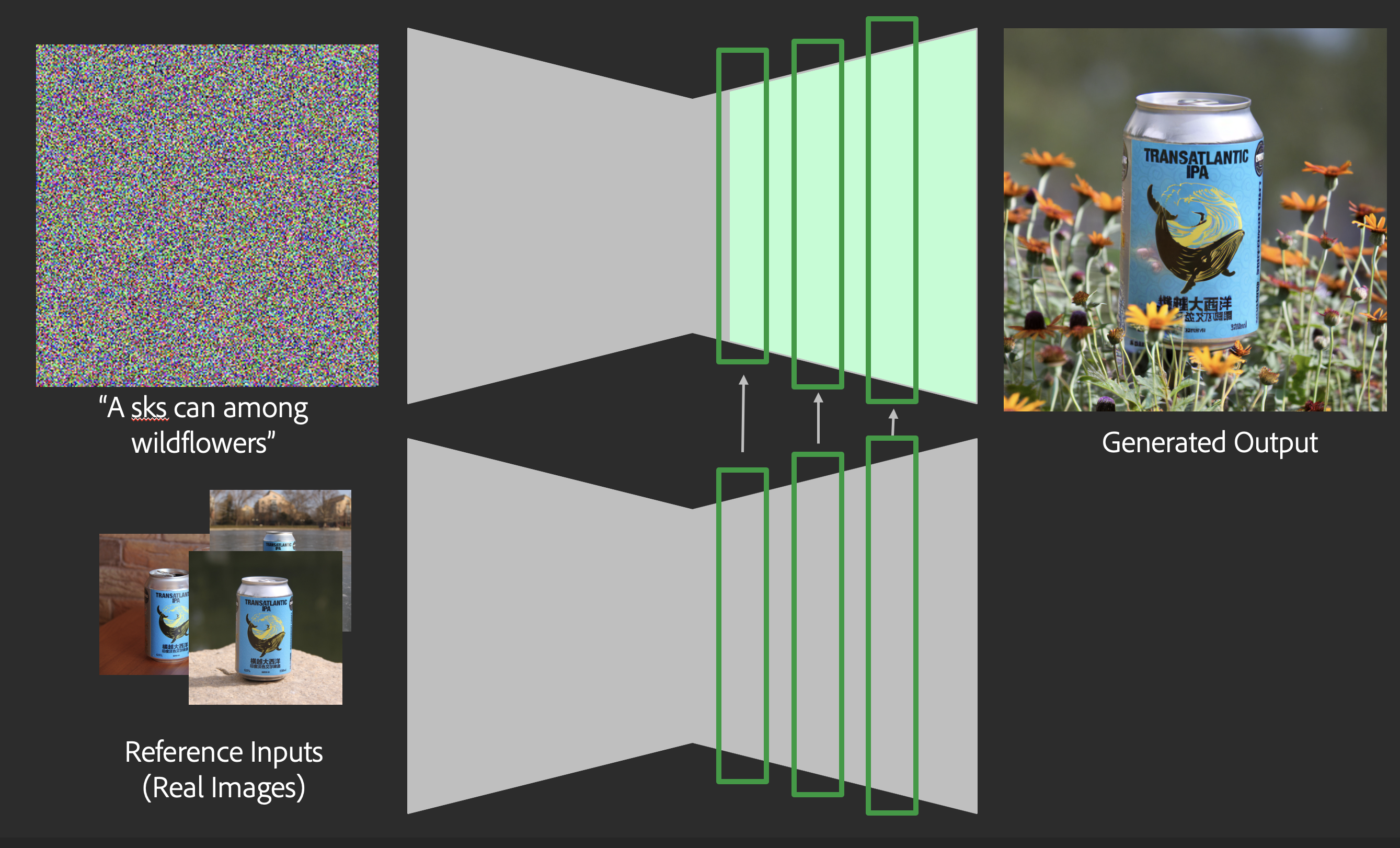
We present a unified diffusion-based framework for content customization and composition in images. Unlike traditional approaches that require separate specialized models and expensive fine-tuning for tasks such as custom image generation, object insertion, and localized editing, our method performs all these operations via a single model and novel training and inference strategies. Key innovations include generic content insertion and harmonization into user-provided backgrounds, text- and image-conditioned editing and styling, attention-based blending for seamless integration, and consistent object style control—all without the need for per-object fine-tuning at inference. This enables scalable, efficient, and flexible image creation and editing.





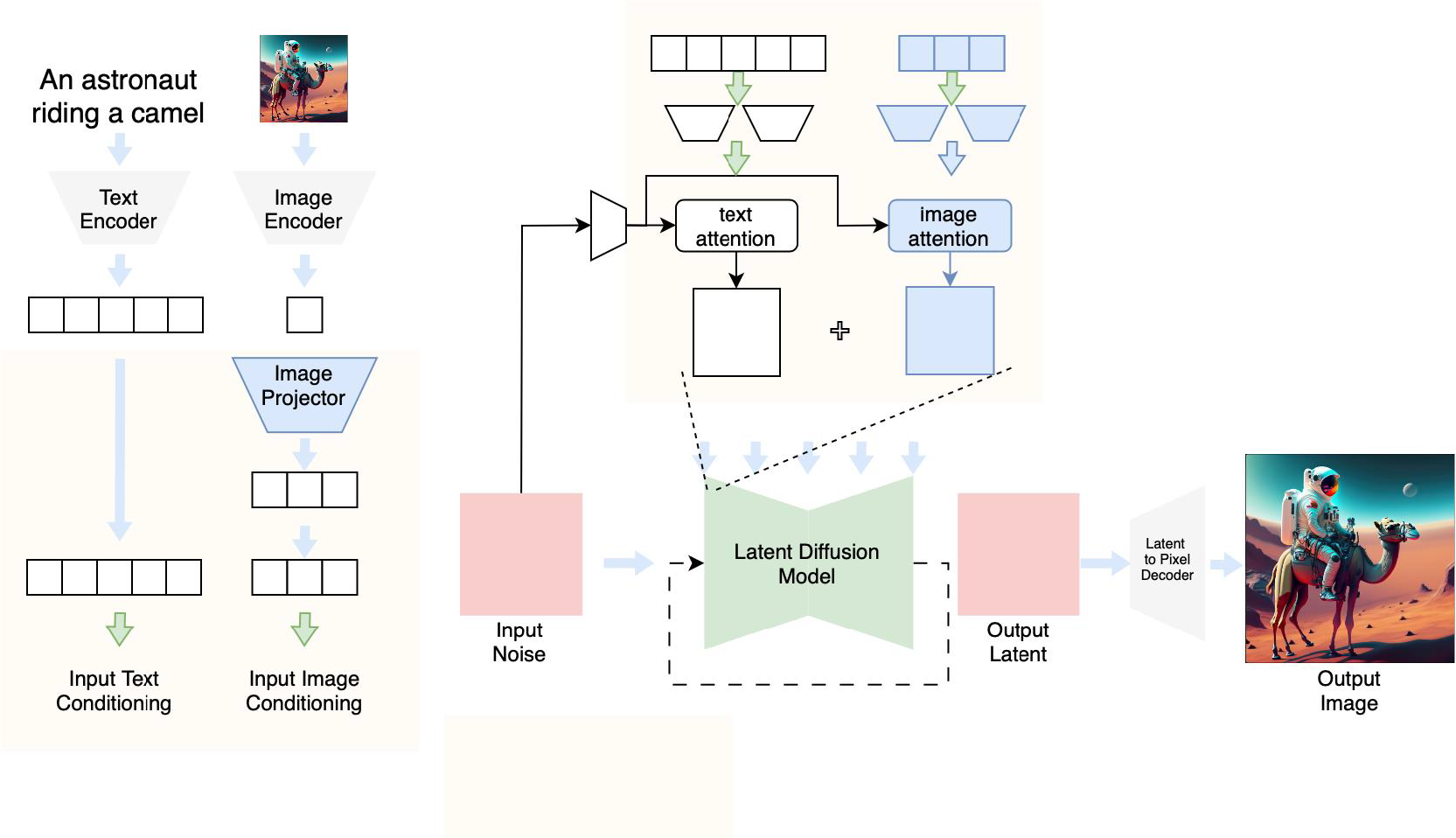
 Multi-concept adaptor learning of multi-modal LLM for image diffusion modelOct 2024US App. 18/953,734
Multi-concept adaptor learning of multi-modal LLM for image diffusion modelOct 2024US App. 18/953,734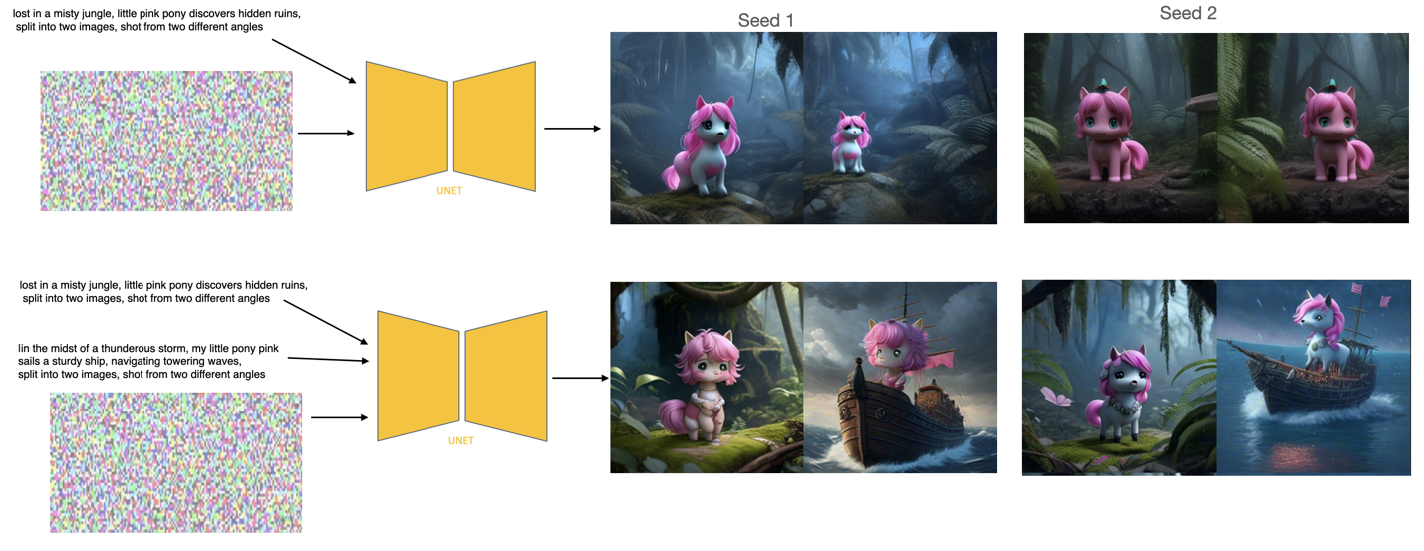
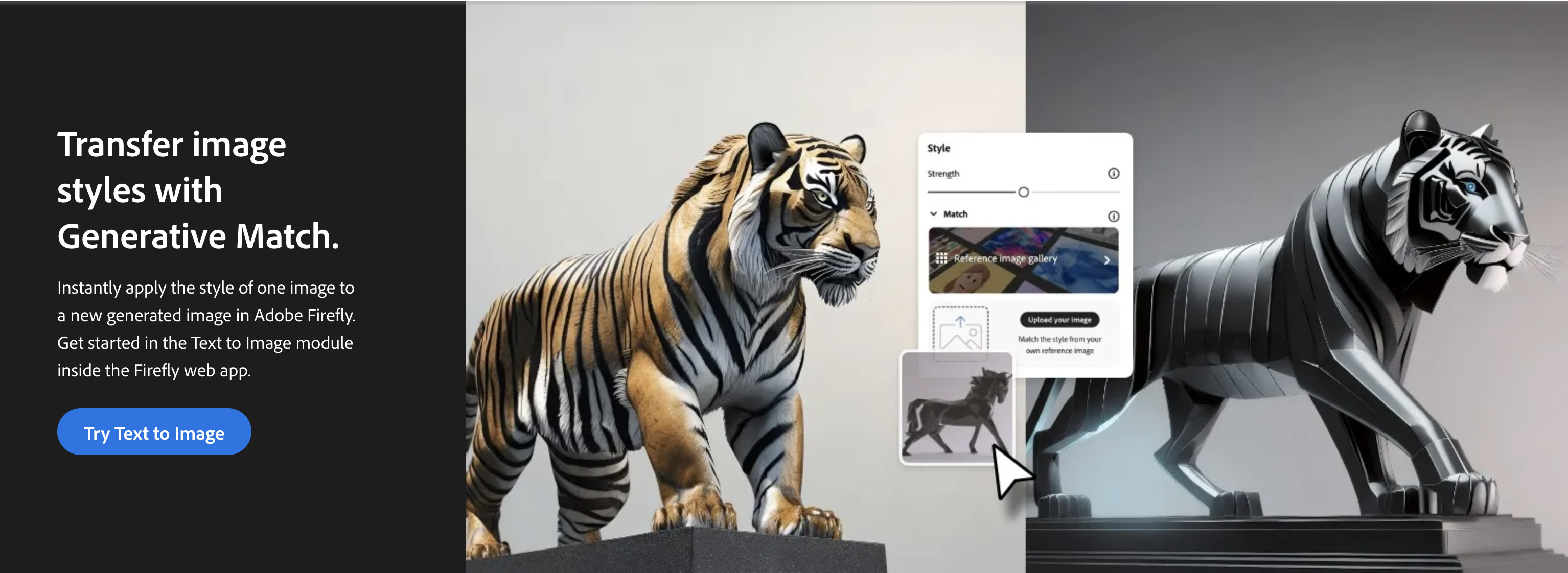
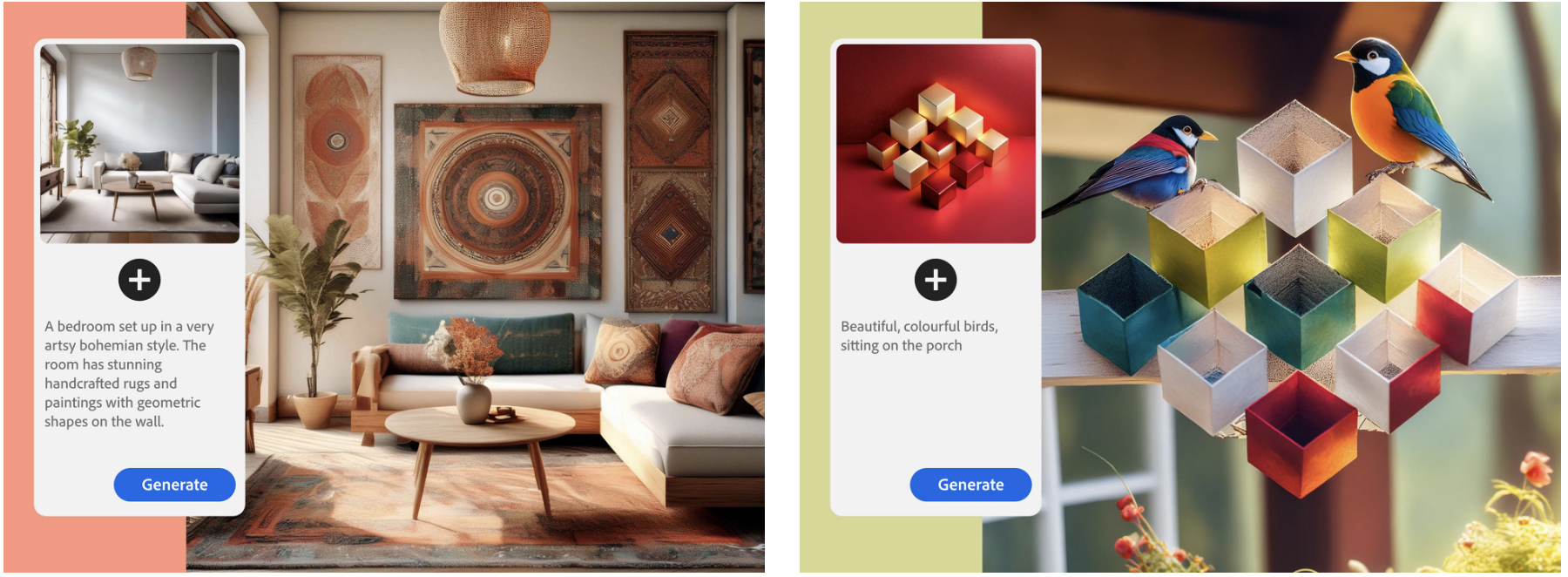
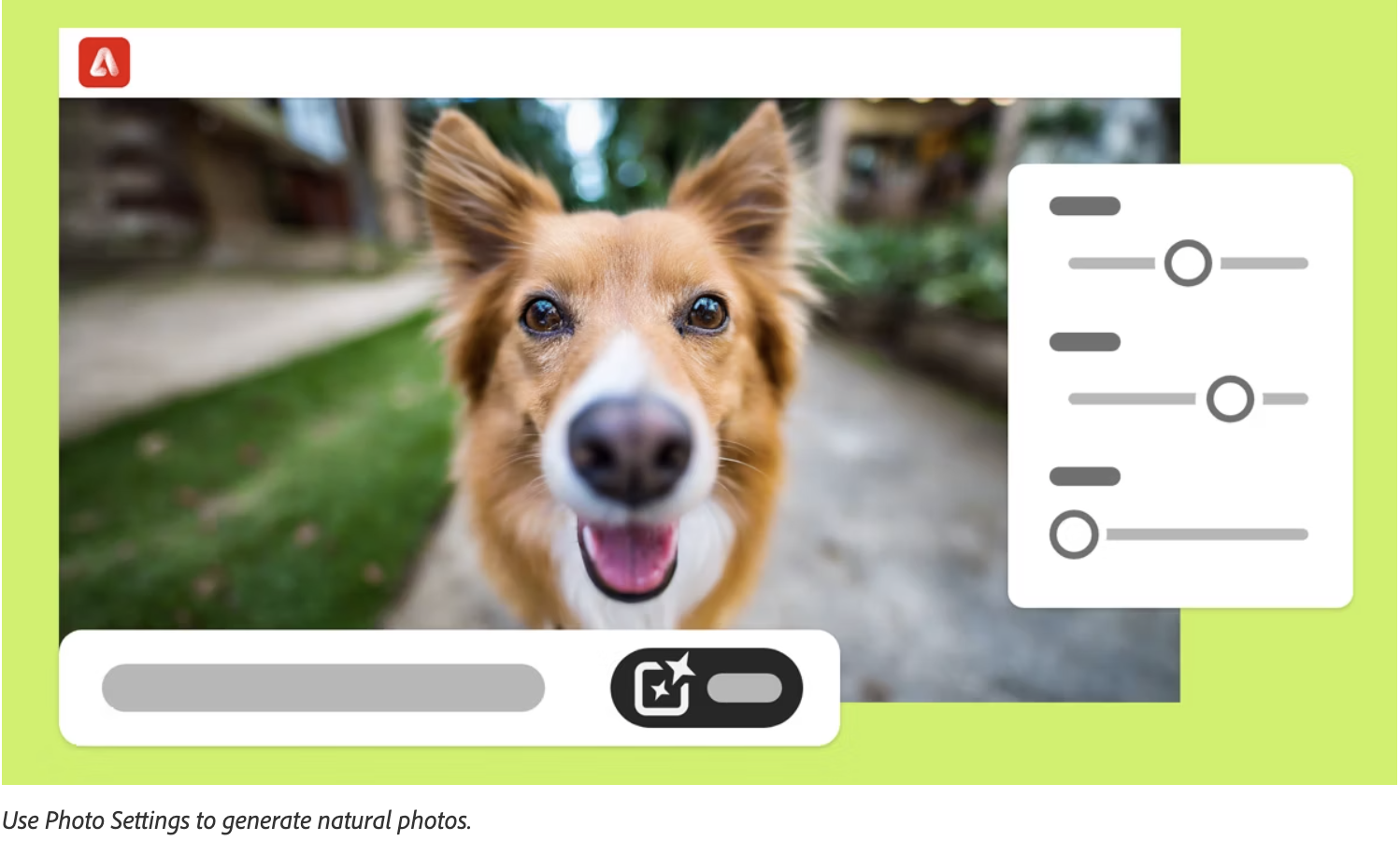

 Score based fine grained control of concept generation using DINO adapterJul 2024US App. 18/785,914
Score based fine grained control of concept generation using DINO adapterJul 2024US App. 18/785,914

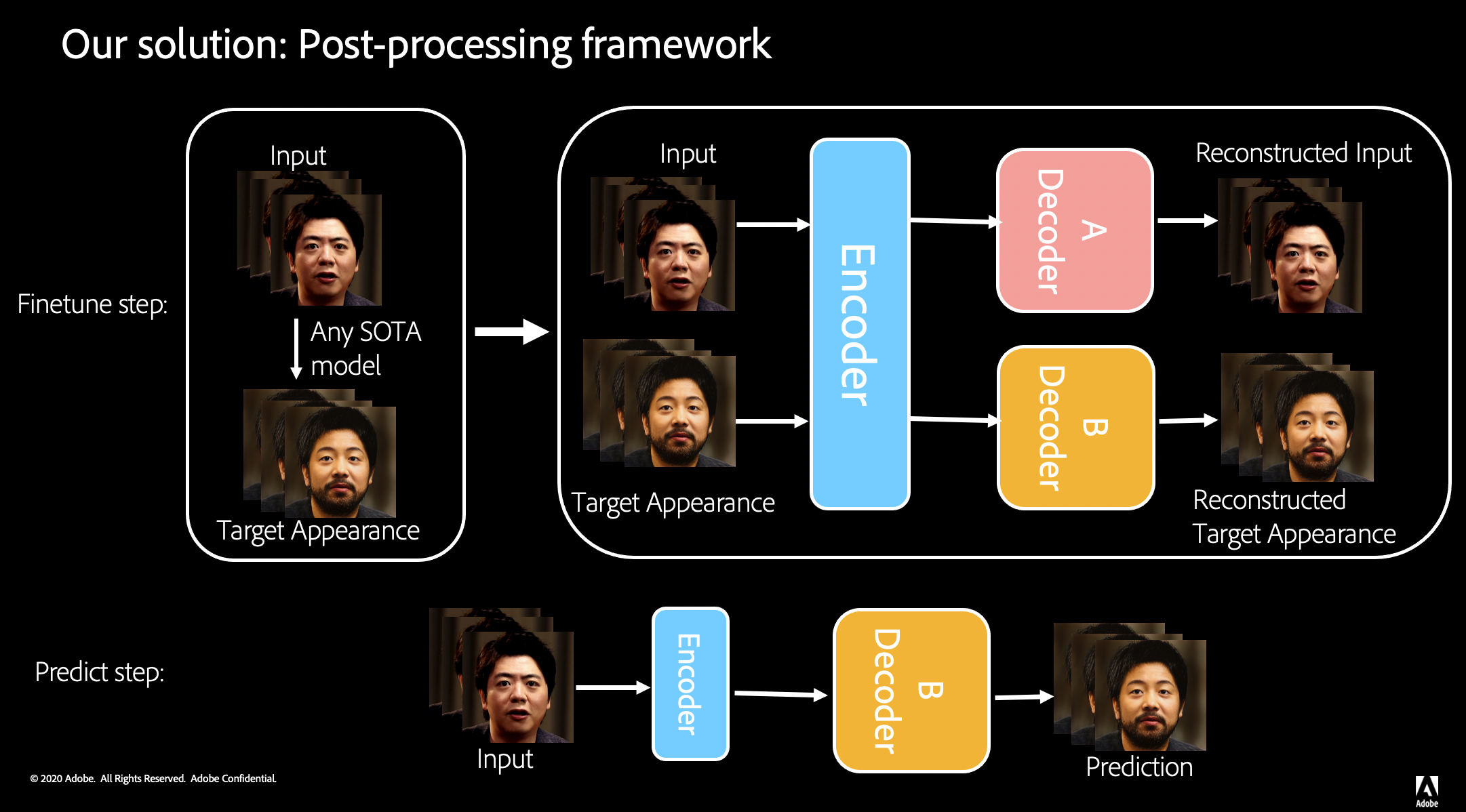
 Face Detection & Identification in After Effects, Premiere Pro, and Elements workflowsMay 2022
Face Detection & Identification in After Effects, Premiere Pro, and Elements workflowsMay 2022




 Waymo driverless car data analysis and driving modeling using CNN and LSTMApr 2020This work contributed to research acknowledged in MDPI Journal of Applied Sciences
Waymo driverless car data analysis and driving modeling using CNN and LSTMApr 2020This work contributed to research acknowledged in MDPI Journal of Applied Sciences